
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- devops
- vm
- docker
- Terraform Cloud
- VAGRANT
- gcp
- terraform
- IAM
- interconnect
- 자격증
- cloud
- cicd
- cloud armor
- kubernetes
- MIG
- Python
- Uptime Check
- AWS
- direnv
- Google Cloud Platform
- Clean Code
- cloud function
- pub/sub
- CentOS
- Java
- 후기
- vpc peering
- github
- 보안 규칙
- 우테캠
- Today
- Total
EMD Blog
HashMap에 대해서 알아보자(1) 본문
이 글은 Java8을 기준으로 작성했습니다.
HashMap
HashMap (Java Platform SE 8 )
If the specified key is not already associated with a value (or is mapped to null), attempts to compute its value using the given mapping function and enters it into this map unless null. If the function returns null no mapping is recorded. If the function
docs.oracle.com
HashMap은 Key, Value의 Entry를 가지는 Java의 대표적인 Map 구현체 중 하나이다. HashMap에 대해 알아보려면 그전에 해시 함수에 대해 잠깐 살펴보고 갈 필요가 있다. 해시 함수(Hash Function)란 임의의 데이터를 고정 길의의 값으로 매핑해주는 함수를 말하며, 여기서 매핑된 고정 값을 해시 값, 해시 코드, 해시 섬 등으로 부른다. 대표적인 사용 예시는 비밀번호 암호화로 들 수 있다. 각 사용자는 임의의 비밀번호를 입력할 것이고 서비스 제공자는 보안상 해당 비밀번호들을 암호화해서 저장해야할 필요가 있다. 그때 해시 함수를 사용하면 비밀번호를 암호화할 수 있다.
원본 비밀번호 : 12345QWE! -(해시 함수)-> 해시 값 : andjwk1u24h1i4327723ad
간단하게 예시를 들면 위와 같다. 그럼 이런 해시 함수가 자료구조에서 어떻게 활용되고 있는지 확인해보자.
먼저 키 값을 쌍으로 갖는 샘플 데이터를 보자
| 차종 | 차급 |
| 아반떼 | 준중형 |
| 소나타 | 중형 |
| K3 | 준중형 |
| 그랜저 | 준대형 |
간단한 차종(Key)과 차급(Value)이다. 이 데이터들을 자료구조에 저장하기 위해서는 먼저 충분한 길이의 리스트를 만들어야 한다.
임시로 길이가 10정도되는 리스트를 생성하도록 하자.
| Index | 차종 | 차급 |
| 0 | ||
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 | ||
| 8 | ||
| 9 |
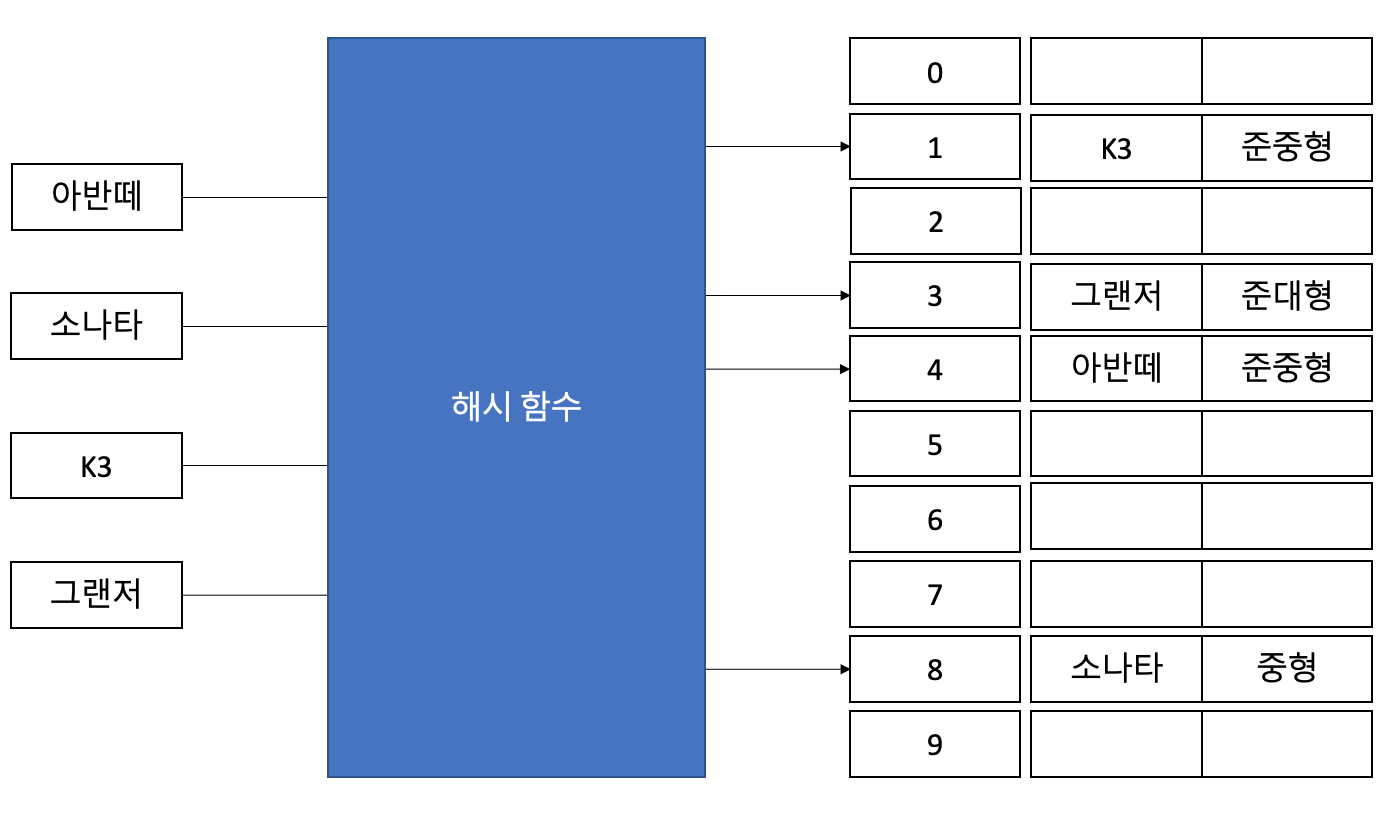
이 다음에는 차종(Key)을 해시 함수를 이용해 Index(0~9)로 매핑한다.
아반떼 -(해시 함수)-> 4
소나타 -(해시 함수)-> 8
K3 -(해시 함수)-> 1
그랜저 -(해시 함수)-> 3
그 다음에는 각 데이터에 맞는 Index(해시 값)에 데이터를 저장한다.
| Index | 차종 | 차급 |
| 0 | ||
| 1 | K3 | 준중형 |
| 2 | ||
| 3 | 그랜저 | 준대형 |
| 4 | 아반떼 | 준중형 |
| 5 | ||
| 6 | ||
| 7 | ||
| 8 | 소나타 | 중형 |
| 9 |
이렇게 하면 위와 같이 데이터를 저장하게 된다. 즉, 아래 그림과 같은 흐름이 된다.
그럼 이제 데이터에 저장을 했으니 접근을 해보도록 하자.
접근은 그냥 차종을 해시 함수로 변환 후 해시 값으로 리스트에 접근하면 된다. ( Array[f('차종')] , f('차종') == 배열 index)
접근 방식에서 눈치 챘겠지만 순회나 정렬을 통한 검색을 필요로하지 않기 때문에 비용이 적게 들고 성능이 훨씬 좋다.
그렇다면 해시 함수에서 항상 문제가 되는 충돌은 어떻게 처리할까? 해시 함수 자료구조에서는 이러한 충돌을 개별 체이닝(Separate Chaining) 방식과 오픈 어드레싱(Open Addressing) 방식으로 처리한다. 개별 체이닝은 다른 두 원본 데이터 값(여기서는 차종)에 대한 해시 값이 동일해서 충돌이 일어날 경우 요소를 연결 리스트로 연결해서 저장하는 방식이고 오픈 어드레싱 방식은 충돌이 일어날 경우 충돌 지점에서부터 순회를 시작해 비어있는 공간을 찾아 데이터를 저장하는 방식이다. Java에서는 개별 체이닝 방식을 채택해 사용하고 있는데 Java8의 경우 개별 체이닝 방식을 연결 리스트를 이용해 유지하다가 데이터 양이 많아지면 트리 형식으로 변경하고 데이터 양이 다시 적어지면 연결 리스트로 변경하는 방식을 채택하고 있다.
결과적으로 해시 함수 이용한 자료구조는 다음과 같은 특징을 가진다.
1. 검색 및 삽입에 대한 비용이 적게들고 성능이 좋음
2. Java 기준으로 개별 체이닝(Separate Chaining) 방식을 채택하여 충돌 해결
HashMap과 HashTable은 위에서 여태까지 설명한 해시 함수 자료구조 형식을 채택하고 있기 때문에 위의 특징들을 전부 가지고 있다. 그럼 이제 HashMap이 어떤 기능을 지원하고 있는지 살펴보도록 하자
생성자(Constructors)
| 생성자 | 설명 |
| HashMap() | 생성자의 인자가 없을 경우 기본 값으로 버킷 크기를 16, 부하율 0.75값으로 생성한다. 부하율(load factor)의 경우 해시 버킷 크기를 2배로 확장 시 임계점 계산에 사용된다. (임계점 : 데이터 개수가 load factor * 현재의 해시 버킷 개수) |
| HashMap(int initialCapacity) | 버킷 크기를 인자로 생성할 수 있다. 부하율은 기본 값인 0.75로 생성된다. |
| HashMap(int initialCapacity, float loadFactor) | 버킷 크기와 부하율을 인자로 받아서 생성할 수 있다. |
| HashMap(Map<? extends K,? extends V> m) | Map 객체를 인자로 생성할 수 있다. 이 경우 인자로 전달된 Map의 요소들을 그대로 매핑한다. |
메서드
| 메서드 | 리턴 값 설명 |
|
| clear() Map 내 모든 매핑을 제거 |
void | |
| clone() 얕은 복사본을 반환, 키와 값 자체는 복제되지 않음 |
Object | |
| compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) 첫 번째 인자로 보낸 키에 해당하는 값을 두번째 인자로 보낸 람다식으로 계산함 ex) hashMap.compute("A", (k,v) => v + 1) // 키 A에 해당하는 값에 +1을 해서 다시 매핑 반환값은 compute 연산 후의 결과값을 반환 |
V | |
| computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) compute와 동일하나 key에 해당하는 값이 null일 경우에만 mappingFunction을 수행 그래서 매개변수 명을 보면 remappingFunction이 아니고 mappingFunction이다 |
V | |
| computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) compute와 동일하나 key에 해당하는 값이 null이 아닐 경우에만 remappingFunction을 수행 |
V | |
| containsKey(Object key) 인자로 보낸 키에 대한 매핑 값이 존재할 경우 true를 반환 |
boolean | |
| containsValue(Object value) 인자로 보낸 값에 대한 키가 존재할 경우 true를 반환 |
boolean | |
| entrySet() Map 내 키,값 entry쌍 전체를 Set<Map.Entry<K,V>> 형식으로 반환 |
Set<Map.Entry<K,V>> | |
| forEach(BiConsumer<? super K, ? super V> action) Map 전체를 순회하며, 키,값을 인자로 하는 람다식 작성하여 수행할 수 있음 |
void | |
| get(Object key) 인자로 보낸 키에 대한 매핑 값을 반환, 매핑이 없으면 null 반환 |
V | |
| getOrDefault(Object key, V defaultValue) 인자로 보낸 키에 대한 매핑 값을 반환, 매핑이 없으면 두 번째 인자로 보낸 값을 반환 |
V | |
| isEmpty() Map이 비어있으면 true를 반환 |
boolean | |
| keySet() Map 내 key 전체를 반환 |
Set<K> | |
| merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) 첫 번째 인자로 보낸 key에 대한 매핑 값이 없거나 null이면 첫 번째 인자에 대한 매핑 값은 두 번째 인자로 보낸 값이 되며, 첫 번째 인자로 보낸 key에 대한 매핑값이 존재 하면 세 번째 인자로 보낸 remappingFunction 연산 값이 매핑 값이 된다. remappingFunction의 경우 첫 번째 인자로 기존 매핑 값을 전달 받고 두 번째 인자로 새로운 매핑 값(merge에 대한 두 번째 인자)을 전달 받는다.매핑된 값 반환 |
V | |
| put(K key, V value) 첫 번째 인자로 보낸 key에 두 번째 인자로 보낸 value를 매핑 새로운 매핑 전의 값을 반환 (신규 매핑일 경우 null반환) |
V | |
| putAll(Map<? extends K, ? extends V> m) 인자로 보낸 맵의 모든 매핑을 복사 (주소 값 참조에 주의) |
void | |
| putIfAbsent(K key, V value) 첫 번째 인자로 보낸 key에 대한 매핑 값이 없거나 Null일 경우 두 번째 인자로 보낸 value를 매핑하고 null을 반환 첫 번째 인자로 보낸 key에 대한 매핑 값이 존재할 경우 새로운 매핑없이 현재 값만 반환 |
V | |
| remove(Object key) 맵이 비어있지 않다면 인자로 보낸 key에 대한 매핑을 제거 매핑이 제거되기 이전 값을 반환 (매핑이 없었을 경우 null 반환) |
V | |
| remove(Object key, Object value) 첫 번째로 보낸 key에 대한 매핑 값이 두 번째 인자로 보낸 value값과 일치할 경우 매핑을 제거 매핑이 제거된 경우 true 반환 |
boolean | |
| replace(K key, V value) 첫 번째 인자로 보낸 key에 대한 매핑 값을 두 번째 인자로 보낸 value로 변경 변경 전 매핑 값을 반환 |
V | |
| replace(K key, V oldValue, V newValue) 첫 번째 인자로 보낸 key에 대한 매핑 값이 두 번째 인자로 보낸 oldValue값과 일치할 경우 newValue로 변경 변경 성공시 true 반환 |
boolean | |
| replaceAll(BiFunction<? super K, ? super V, ? extends V> function) 맵을 순회하면서 key와 매핑 값을 인자로 받는 람다식을 계산해 인자로 받은 key에 리매핑 |
void | |
| size() 매핑 수 반환 |
int | |
| values() Map 내 매핑 값 전체를 반환 |
Collection<V> | |
이렇게 HashMap에 대해 간단하게 알아보았다. 다음에는 더 자세하게 알아보도록 하자.
[참고자료]
'개발 > Java' 카테고리의 다른 글
| JVM에 대해 알아보자 (0) | 2021.05.15 |
|---|